在数据库中存储一棵树,实现无限级分类
发布时间:
最后更新:
原创文章,转载请注明原文链接 https://blog.kaciras.com/article/6/store-tree-in-database
在一些系统中,对内容进行分类是必需的功能。比如电商就需要对商品做分类处理,以便于客户搜索;论坛也会分为很多板块;门户网站、也得对网站的内容做各种分类。
分类对于一个内容展示系统来说是不可缺少的,本博客也需要这么一个功能。众所周知,分类往往具有从属关系,比如铅笔盒钢笔属于笔,笔又是文具的一种,当然钢笔还可以按品牌来细分,每个品牌下面还有各种系列...
这个例子中从属关系具有5层,从上到下依次是:文具-笔-钢笔-XX牌-A系列,但实际中分类的层数却是无法估计的,比如生物中的界门纲目科属种有7级。显然对分类的级数做限制是不合理的,一个良好的分类系统,其应当能实现无限级分类。
 本博客的分类标签
本博客的分类标签
在写自己的博客网站时,刚好需要这么一个功能。
完整的代码以及动态演示见 https://github.com/Kaciras/ClosureTable
需求分析 #
首先分析一下分类之间的关系是怎样的,很明显,一个分类下面有好多个下级分类,比如笔下面有铅笔和钢笔;那么反过来,一个下级分类能够属于几个上级分类呢?这其实并不确定,取决于如何对类型的划分。比如有办公用品和家具,那么办公桌可以同时属于这两者,不过这会带来一些问题,比如:我要显示从顶级分类到它之间的所有分类,那么这种情况下就很难决定办公用品和家具显示哪一个,并且如果是多对一,实现上将更加复杂,所以这里还是限定每个分类仅有一个上级分类。
这样一来,分类的关系可以表述为一父多子的继承关系,正好对应数据结构中的树,那么问题就转化成了如何在数据库中存储一棵树,并且对分类所需要的操作有较好的支持。
对于本博客来说,分类至少需要以下操作:
- 对单个分类的增删改查。
- 查询一个分类的直属下级和所有下级,在现实某一分类下所有文章时需要使用。
- 查询出由顶级分类到文章所在分类之间的所有分类,并且是有序的。
- 查询分类是哪一级的,比如顶级分类是1,顶级分类的直属下级是2,再往下依次递增。
- 移动一个分类,换句话说就是把一个子树(或者仅单个节点)移动到另外的节点下面,这个在分类结构不合理,需要修改时使用。
在性能的衡量上,这些操作并不是平等的。查询操作使用的更加频繁,毕竟分类不会没事就改着玩,性能考虑要以查询操作优先,特别是2和3分别用于搜索文章和在文章简介中显示其分类,所以是重中之重。
另外,每个分类除了继承关系外,还有名字,简介等属性,也需要存储在数据库中。每个分类都有一个id,由数据库自动生成(自增主键)。
无限级多分类多存在于企业应用中,比如电商、博客平台等,这些应用里一般都有缓存机制,对于分类这种不频繁修改的数据,即使在底层数据库中存在缓慢的操作,只要上层缓存能够命中,一样有很快的响应速度。但是对于抽象的需求:在关系数据库中存储一棵树,并不仅仅存在于有缓存的应用中,所以设计一个高效的存储方案,仍然有其意义。
下面就以这个卖文具的电商的场景为例,针对这6条需求,设计一个数据库存储方案(对过程没兴趣可以直接转到第4节)。
一些常见设计方案的不足 #
直接记录父分类的引用 #
在许多编程语言中,继承关系都是一个类仅继承于一个父类,添加这种继承关系仅需要声明一下父类即可,比如JAVA中extends xxx。根据这种思想,我们仅需要在每个分类上添加上直属上级的id,即可存储它们之间的继承关系。
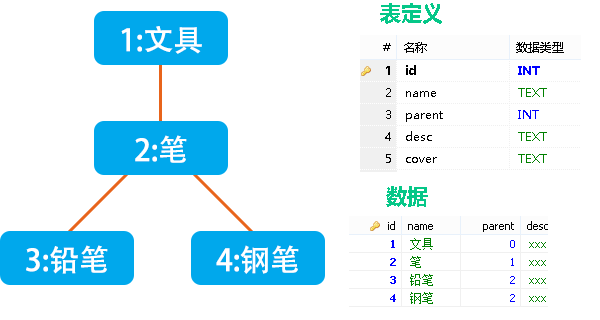 父id字段存储继承关系
表中
父id字段存储继承关系
表中parent即为直属上级分类的id,顶级分类设为0。这种方案简单易懂,仅存在一张表,并且没有冗余字段,存储空间占用极小,在数据库层面是一种很好的设计。
那么再看看对操作的支持情况怎么样,第一条单个增改查都是一句话完事就不多说了,删除的话记得把下级分类的id全部改成被删除分类的上级分类即可,也就多一个UPDATE。
第二条可就麻烦了,比如我要查文具的下级分类,预期结果是笔、铅笔、钢笔三个,但是并没有办法通过文具一次性就查到铅笔盒钢笔,因为这两者的关系间接存储在笔这个分类里,需要先查出直属下级(笔),才能够往下查询,这意味着需要递归,性能上一下子就差了很多。
第三条同样需要递归,因为通过一个分类,数据库中只存储了其直属父类,需要通过递归到顶级分类才能获取到它们之间的所有分类信息。
综上所述,最关键的两个需求都需要使用性能最差的递归方式,这种设计肯定是不行的。但还是继续看看剩下的几条吧。
第4个需求:查询分类是哪一级的?这个还是得需要递归或循环,查出所有上级分类的数量即为分类的层级。
移动分类倒是非常简单,直接更新父id即可,这也是这种方案的唯一优势了吧...如果你的分类修改比查询还多不妨就这么做吧。
最后一个查询某一级的所有分类,对于这个设计简直是灾难,它需要先找出所有一级分类,然后循环一遍,找出所有一级分类的子类就是二级分类...如此循环直到所需的级数为之。所以这种设计里,这个功能基本是废了。
这个方式也是一开始就能想到的,在数据量不大(层级不深)的情况下,因为其简单直观的特点,不失为一个好的选择,不过对于本项目来说还不够(本项目立志成为一流博客平台!!!)。
路径列表 #
从2.1节中可以看出,__之所以速度慢,就是因为在分类中仅仅存储了直属上级的关系,而需求却要查询出非直属上级。__针对这一点,我们的表中不仅仅记录父节点id,而是将它到顶级分类之间所有分类的id都保存下来。这个字段所保存的信息就像文件树里的路径一样,所以就叫做path吧。
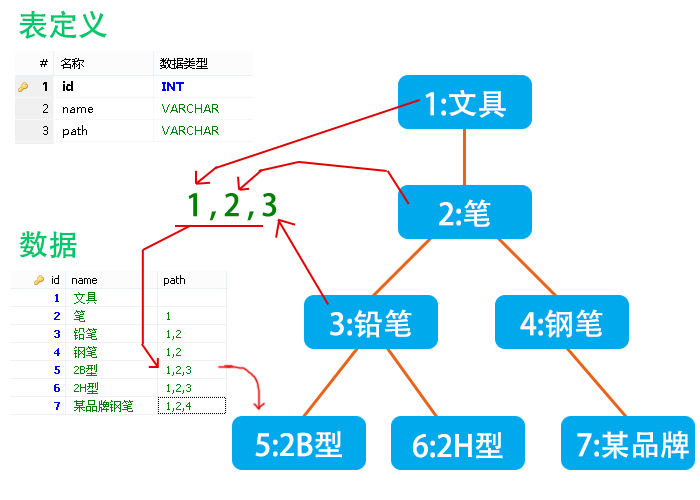 路径列表设计
路径列表设计
如图所示,每个分类保存了它所有上级分类的列表,用逗号隔开,从左往右依次是从顶级分类到父分类的id。
查询下级时使用Like运算符来查找,比如查出所有笔的下级:
SELECT id,name FROM pathlist WHERE path LIKE '1,%'
一句话搞定,LIKE的右边是笔的path字段的值加上模糊匹配,并且左联接能够使用索引,的效率也过得去。
查询笔的直属下级也同样可以用LIKE搞定:
SELECT id,name FROM pathlist WHERE path LIKE '%2'
而找出所有上级分类这个需求,直接查出path字段,然后在应用层里分割一下即可获得获得所有上级,并且顺序也能保证。
查询某一级的分类也简单,因为层级越深,path就越长,使用LENGTH()函数作为条件即可筛选出合适的结果。反过来,根据其长度也能够计算出分类的级别。
移动操作需要递归,因为每一个分类的path都是它父类的path加上父类的id,将分类及其所有子分类的path设为其父类的path并在最后追加父类的id即可。
在许多系统中都使用了这种方案,其各方面都具有可以接受的性能,理解起来也比较容易。但是其有两点不足:1.就是不遵守数据库范式,将列表数据直接作为字符串来存储,这将导致一些操作需要在上层解析path字段的值;2.就是字段长度是有限的,不能真正达到无限级深度,并且大字段对索引不利。如果你不在乎什么范式,分类层级也远达不到字段长度的限制,那么这种方案是可行的。
前序遍历树 #
这是一种在数据库里存储一棵树的解决方案。它的思想不是直接存储父节点的id,而是以前序遍历中的顺序来判断分类直接的关系。
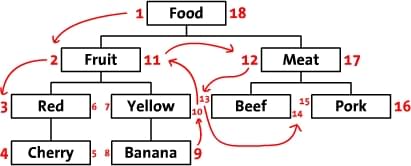 前序遍历树
前序遍历树
假设从根节点开始以前序遍历的方式依次访问这棵树中的节点,最开始的节点(“Food”)第一个被访问,将它左边设为1,然后按照顺序到了第二个阶段“Fruit”,给它的左边写上2,每访问一个节点数字就递增,访问到叶节点后返回,在返回的过程中将访问过的节点右边写也写上数字。这样,在遍历中给每个节点的左边和右边都写上了数字。最后,我们回到了根节点“Food”在右边写上18。下面是标上了数字的树,同时把遍历的顺序用箭头标出来了。
我们称这些数字为左值和右值(如,“Meat”的左值是12,右值是17),这些数字包含了节点之间的关系。因为“Red”有3和6两个值,所以,它是有拥有1-18值的“Food”节点的后续。同样的,可以推断所有左值大于2并且右值小于11的节点,都是有2-11的“Fruit” 节点的后续。这样,树的结构就通过左值和右值储存下来了。
这里就不贴表结构了,这种方式不如前面两种直观。效率上,查询全部下级的需求被很好的解决,而直属下级也可以通过添加父节点id的parent字段来解决。
因为左值更大右值更小的节点是下级节点,反之左值更小、右值更大的就是上级,故需求3:查询两个分类直接的所有分类可以通过左右值作为条件来解决,同样是一次查询即可。
添加新分类和删除分类需要修改在前序遍历中所有在指定节点之后的节点,甚至包括非父子节点。而移动分类也是如此,这个特性就非常不友好,在数据量大的情况下,改动一下可是很要命的。
查询某一级的所有分类,和查询分类是哪一级的,这两个需求无法解决,只能通过parent字段想第一种方式一样慢慢遍历。
综上所述,对于本项目而言,它还不如第二种,所以这个很复杂的方案也得否决掉。
新方案的思考 #
上面几种方案最接近理想的就是第二种,如果能解决字段长度问题和不符合范式,以及需要上层参与处理的问题就好了。不过不要急,先看看第二种方案的的优缺点的本质是什么。
在分析第二种方案的开头就提到,要确保效率,必须要在分类的信息中包含所有上级分类的信息,而不能仅仅只含有直属上级,所以才有了用一个varchar保存列表的字段。但反过来想想,数据库的表本身不就是用来保存列表这样结构化数据集合的工具吗,为何不能用一张表来代替path字段呢?
在路径列表的设计中,关键字段path的本质是把一个数组存在了一列里,而这个数组包含两个信息:数组的元素为上层节点的id,数组的下标对应层级。 所以另增一张表,含有三个字段:一个是本分类的所有上级的id,一个是本分类的id,再加上该分类到每个上级分类的距离。这样这张表就能够起到与path字段相同的作用,而且还不违反数据库范式,最关键的是它不存在字段长度的限制!
经过一番折腾,终于找到了这个比较完美的方案。事实上在之后的查阅资料中,发现这个方案早就在一些系统中使用了,名叫ClosureTable。
基于 ClosureTable 的存储 #
ClosureTable直译过来叫闭包表?不过不重要,ClosureTable以一张表存储节点之间的关系、其中包含了任何两个有关系(上下级)节点的关联信息
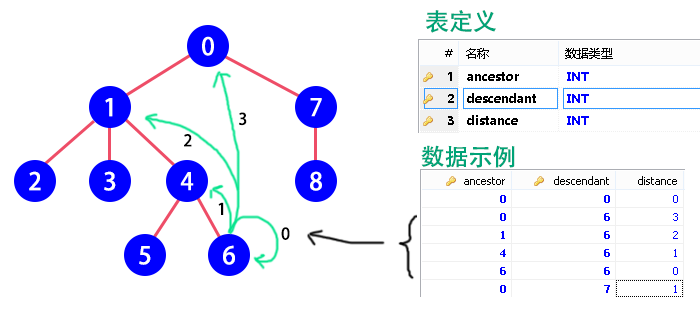 ClosureTable演示
ClosureTable演示
定义关系表CategoryTree,其包含3个字段:
ancestor祖先:上级节点的iddescendant子代:下级节点的iddistance距离:子代到祖先中间隔了几级
这三个字段的组合是唯一的,因为在树中,一条路径可以标识一个节点,所以可以直接把它们的组合作为主键。以图为例,节点6到它上一级的节点(节点4)距离为1在数据库中存储为ancestor=4,descendant=6,distance=1,到上两级的节点(节点1)距离为2,于是有ancestor=1,descendant=6,distance=2,到根节点的距离为3也是如此,最后还要包含一个到自己的连接,当然距离就是0了。
这样一来,不仅表中包含了所有的路径信息,还在带上了路径中每个节点的位置(距离),对于树结构常用的查询都能够很方便的处理。下面看看如何用用它来实现我们的需求。
子节点查询 #
查询id为5的节点的直属子节点:
SELECT descendant FROM CategoryTree WHERE ancestor=5 AND distance=1
查询所有子节点:
SELECT descendant FROM CategoryTree WHERE ancestor=5 AND distance>0
查询某个上级节点的子节点,换句话说就是查询具有指定上级节点的节点,也就是ancestor字段等于上级节点id即可,第二个距离distance决定了查询的对象是由上级往下那一层的,等于1就是往下一层(直属子节点),大于0就是所有子节点。这两个查询都是一句完成。
路径查询 #
查询由根节点到id为10的节点之间的所有节点,按照层级由小到大排序
SELECT ancestor FROM CategoryTree WHERE descendant=10 ORDER BY distance DESC
查询id为10的节点(含)到id为3的节点(不含)之间的所有节点,按照层级由小到大排序
SELECT ancestor FROM CategoryTree WHERE descendant=10 AND
distance<(SELECT distance FROM CategoryTree WHERE descendant=10 AND ancestor=3)
ORDER BY distance DESC
查询路径,只需要知道descendant即可,因为descendant字段所在的行就是记录这个节点与其上级节点的关系。如果要过滤掉一些则可以限制distance的值。
查询节点所在的层级(深度) #
查询id为5的节点是第几级的
SELECT distance FROM CategoryTree WHERE descendant=5 AND ancestor=0
查询id为5的节点是id为10的节点往下第几级
SELECT distance FROM CategoryTree WHERE descendant=5 AND ancestor=10
查询层级(深度)非常简单,因为distance字段就是。直接以上下级的节点id为条件,查询距离即可。
查询某一层的所有节点 #
查询所有第三层的节点
SELECT descendant FROM CategoryTree WHERE ancestor=0 AND distance=3
这个就不详细说了,非常简单。
插入 #
插入和移动就不是那么方便了,当一个节点插入到某个父节点下方时,它将具有与父节点相似的路径,然后再加上一个自身连接即可。
所以插入操作需要两条语句,第一条复制父节点的所有记录,并把这些记录的distance加一,因为子节点到每个上级节点的距离都比它的父节点多一。当然descendant也要改成自己的。
例如把id为10的节点插入到id为5的节点下方(这里用了Mysql的方言)
INSERT INTO CategoryTree(ancestor,descendant,distance) (SELECT ancestor,10,distance+1 FROM CategoryTree WHERE descendant=5)
然后就是加入自身连接的记录。
INSERT INTO CategoryTree(ancestor,descendant,distance) VALUES(10,10,0)
移动 #
节点的移动没有很好的解决方法,因为新位置所在的深度、路径都可能不一样,这就导致移动操作不是仅靠UPDATE语句能完成的,这里选择删除+插入实现移动。
另外,在有子树的情况下,上级节点的移动还将导致下级节点的路径改变,所以移动上级节点之后还需要修复下级节点的记录,这就需要递归所有下级节点。
删除id=5节点的所有记录
DELETE FROM CategoryTree WHERE descendant=5
然后配合上面一节的插入操作实现移动。具体的实现直接上代码吧。
ClosureTableCategoryStore.java是主要的逻辑,这里只展示部分代码
/**
* 将一个分类移动到目标分类下面(成为其子分类)。被移动分类的子类将自动上浮(成为指定分类
* 父类的子分类),即使目标是指定分类原本的父类。
* <p>
* 例如下图(省略顶级分类):
* 1 1
* | / | \
* 2 3 4 5
* / | \ move(2,7) / \
* 3 4 5 ---------------> 6 7
* / \ / / | \
* 6 7 8 9 10 2
* / / \
* 8 9 10
*
* @param id 被移动分类的id
* @param target 目标分类的id
* @throws IllegalArgumentException 如果id或target所表示的分类不存在、或id==target
*/
public void move(int id, int target) {
if(id == target) {
throw new IllegalArgumentException("不能移动到自己下面");
}
moveSubTree(id, categoryMapper.selectAncestor(id, 1));
moveNode(id, target);
}
/**
* 将一个分类移动到目标分类下面(成为其子分类),被移动分类的子分类也会随着移动。
* 如果目标分类是被移动分类的子类,则先将目标分类(连带子类)移动到被移动分类原来的
* 的位置,再移动需要被移动的分类。
* <p>
* 例如下图(省略顶级分类):
* 1 1
* | |
* 2 7
* / | \ moveTree(2,7) / | \
* 3 4 5 ---------------> 9 10 2
* / \ / | \
* 6 7 3 4 5
* / / \ |
* 8 9 10 6
* |
* 8
*
* @param id 被移动分类的id
* @param target 目标分类的id
* @throws IllegalArgumentException 如果id或target所表示的分类不存在、或id==target
*/
public void moveTree(int id, int target) {
/* 移动分移到自己子树下和无关节点下两种情况 */
Integer distance = categoryMapper.selectDistance(id, target);
if (distance == null) {
// 移动到父节点或其他无关系节点,不需要做额外动作
} else if (distance == 0) {
throw new IllegalArgumentException("不能移动到自己下面");
} else {
// 如果移动的目标是其子类,需要先把子类移动到本类的位置
int parent = categoryMapper.selectAncestor(id, 1);
moveNode(target, parent);
moveSubTree(target, target);
}
moveNode(id, target);
moveSubTree(id, id);
}
/**
* 将指定节点移动到另某节点下面,该方法不修改子节点的相关记录,
* 为了保证数据的完整性,需要与moveSubTree()方法配合使用。
*
* @param id 指定节点id
* @param parent 某节点id
*/
private void moveNode(int id, int parent) {
categoryMapper.deletePath(id);
categoryMapper.insertPath(id, parent);
categoryMapper.insertNode(id);
}
/**
* 将指定节点的所有子树移动到某节点下
* 如果两个参数相同,则相当于重建子树,用于父节点移动后更新路径
*
* @param id 指定节点id
* @param parent 某节点id
*/
private void moveSubTree(int id, int parent) {
int[] subs = categoryMapper.selectSubId(id);
for (int sub : subs) {
moveNode(sub, parent);
moveSubTree(sub, sub);
}
}
其中的categoryMapper 是Mybatis的Mapper,这里只展示部分代码
/**
* 查询某个节点的第N级父节点。如果id指定的节点不存在、操作错误或是数据库被外部修改,
* 则可能查询不到父节点,此时返回null。
*
* @param id 节点id
* @param n 祖先距离(0表示自己,1表示直属父节点)
* @return 父节点id,如果不存在则返回null
*/
@Select("SELECT ancestor FROM CategoryTree WHERE descendant=#{id} AND distance=#{n}")
Integer selectAncestor(@Param("id") int id, @Param("n") int n);
/**
* 复制父节点的路径结构,并修改descendant和distance
*
* @param id 节点id
* @param parent 父节点id
*/
@Insert("INSERT INTO CategoryTree(ancestor,descendant,distance) " +
"(SELECT ancestor,#{id},distance+1 FROM CategoryTree WHERE descendant=#{parent})")
void insertPath(@Param("id") int id, @Param("parent") int parent);
/**
* 在关系表中插入对自身的连接
*
* @param id 节点id
*/
@Insert("INSERT INTO CategoryTree(ancestor,descendant,distance) VALUES(#{id},#{id},0)")
void insertNode(int id);
/**
* 从树中删除某节点的路径。注意指定的节点可能存在子树,而子树的节点在该节点之上的路径并没有改变,
* 所以使用该方法后还必须手动修改子节点的路径以确保树的正确性
*
* @param id 节点id
*/
@Delete("DELETE FROM CategoryTree WHERE descendant=#{id}")
void deletePath(int id);
结语 #
在分析推论后,终于找到了一种既有查询简单、效率高等优点,也符合数据库设计范式,而且是真正的无限级分类的设计。本方案的写入操作虽然需要递归,但相比于前序遍历树效率仍高出许多,并且在本博客系统中分类不会频繁修改。可见对于在关系数据库中存储一棵树的需求,ClosureTable是一种比较完美的解决方案。